
Cassandra (Apache Cassandra) adalah produk open source untuk menajemen database (DBMS) yang didistribusikan oleh Apache yang sangat scalable (dapat diukur) dan dirancang untuk mengelola data terstruktur dengan jumlah data yang sangat besar. Cassandra memiliki kemampuan untuk menjaga tidak terjadinya single point of failure. Cassandra merupakan salah satu jenis dari NoSQL (Not Only SQL) Database seperti mongoDB. NoSQL merupakan konsep penyimpanan database dinamis yang tidak terikat pada relasi-relasi tabel yang kaku seperti RDBMS. Basis data ini bebas skema, mendukung replikasi dengan mudah, memiliki API sederhana, sehingga memiliki performa pengaksesan yang lebih cepat dan dapat menangani jumlah data yang sangat banyak.
Kemampuan Cassandra dalam menyimpan data dengan jumlah yang sangat besar tidak diragukan lagi, puluhan perusahaan besar telah mempercayakan Cassandra sebagai salah satu penunjang kerja mereka diantaranya:

![]()

![]()

![]()
Untuk memproses datanya, Cassandra menggunakan bahasa sendiri yang mirip dengan SQL yaitu Cassandra Query Language (CQL).
Sejarah Cassandra
- Cassandra dikembangkan di Facebook untuk pencarian kotak masuk.
- Open-source oleh Facebook pada bulan Juli 2008.
- Cassandra diterima menjadi Apache Incubator pada Maret 2009.
- Menjadi proyek top-level Apache sejak Februari 2010.
Fitur
Sama dengan Database NoSQL lainnya, Cassandra mengusung keunggulan-keunggulan seperti
-
Elastic Scalability, Cassandra sangat skalabel, sehingga memungkinkan untuk menambah lebih banyak perangkat keras untuk mengakomodasi lebih banyak pelanggan dan lebih banyak data sesuai kebutuhan.
-
Always on Architecture, Cassandra menjaga tidak terjadinya single point of failure dan selalu tersedia untuk aplikasi bisnis yang kritis yang tidak menerima kesalahan atau kegagalan.
-
Fast Linear-scale Performance, Cassandra dapat diukur secara linear, seperti, meningkatkan throughput Anda saat Anda meningkatkan jumlah node dalam cluster. Karena itu ia mempertahankan waktu respons yang cepat.
-
Flexible Data Storage, Cassandra mengakomodasi semua format data yang ada, termasuk: terstruktur, semi-terstruktur, dan tidak terstruktur. Secara dinamis dapat mengakomodasi perubahan struktur data anda sesuai dengan kebutuhan Anda.
-
Easy Data Distribution, Cassandra memberikan fleksibilitas untuk mendistribusikan data mana yang Anda butuhkan dengan mereplikasi data di beberapa pusat data.
-
Transaction support, Cassandra mendukung properti seperti Atomicity, Consistency, Isolasi, dan Durability (ACID).
-
Fast Writes, Cassandra dirancang untuk berjalan pada perangkat keras low end. Ia melakukan menulis cepat dan dapat menyimpan ratusan terabyte data, tanpa mengorbankan efisiensi membacanya.
Arsitektur
Cassandra di desain awal untuk menghandle Big Data yang terdiri dari banyak titik-titik (node) yang terpisah-pisah dan saling bekerjasama nyaris tanpa ada kesalahan. Cassandra memiliki peer-to-peer sistem terdistribusi di seluruh node, dan data didistribusikan di antara semua node dalam sebuah cluster.
-
Semua node dalam sebuah cluster memainkan peran yang sama. Setiap node independen dan pada saat yang sama saling berhubungan ke node lain.
-
Setiap node dalam sebuah cluster dapat menerima membaca dan menulis permintaan, terlepas dari mana data sebenarnya terletak di cluster.
-
Ketika sebuah node performanya turun, membaca permintaan / tulis dapat dilayani dari node lain dalam jaringan.
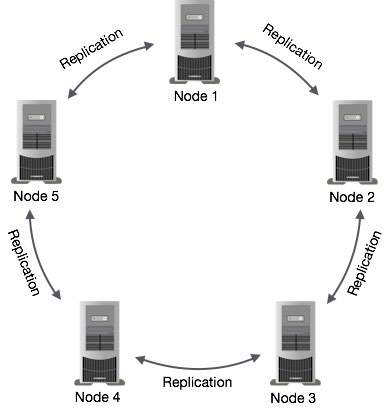
Replikasi data di Cassandra disebut dengan istilah Gossip Protocol dimana satu atau lebih node dalam sebuah Cluster sebagai replika untuk bagian tertentu dari data. Jika terdeteksi bahwa beberapa node datanya out of date, Cassandra akan mengembalikan nilai terbaru untuk klien. Setelah mengembalikan nilai terbaru, Cassandra melakukan perbaikan membaca di latar belakang untuk memperbarui nilai-nilai yang out of date.
Konsep Replication Antar Node Cassandra
Komponen
Cassandra mempunyai beberapa komponen utama yaitu :
-
Node : Node adalah tempat penyimpanan/stored data.
-
Data Center : Kumpulan dari beberapa node.
-
Cluster : Kumpulan dari beberapa data center.
-
Commit Log : Adalah log dari proses penulisan di Cassandra, yang berfungsi juga sebagai Crash Recovery Mechanism.
-
Mem-Table : Adalah memory-resident data structure. Setelah menulis dalam commit log, cassandra melakukan penulisan di sini.
-
SS-Table : Adalah disk file untuk data yang dikeluarkan dari mem-table ketika isinya mencapai nilai ambang batas.
- Bloom filter : Ini tidak lain adalah algoritma yang cepat, tidak deterministik, untuk menguji apakah suatu elemen adalah anggota dari suatu set. Ini adalah jenis cache khusus. Filter Bloom diakses setelah setiap permintaan.
-
CQL : Cassandra Query Language, adalah bahasa perintah query di cassandra.
Referensi:
http://cassandra.apache.org/
https://www.tutorialspoint.com/cassandra/
